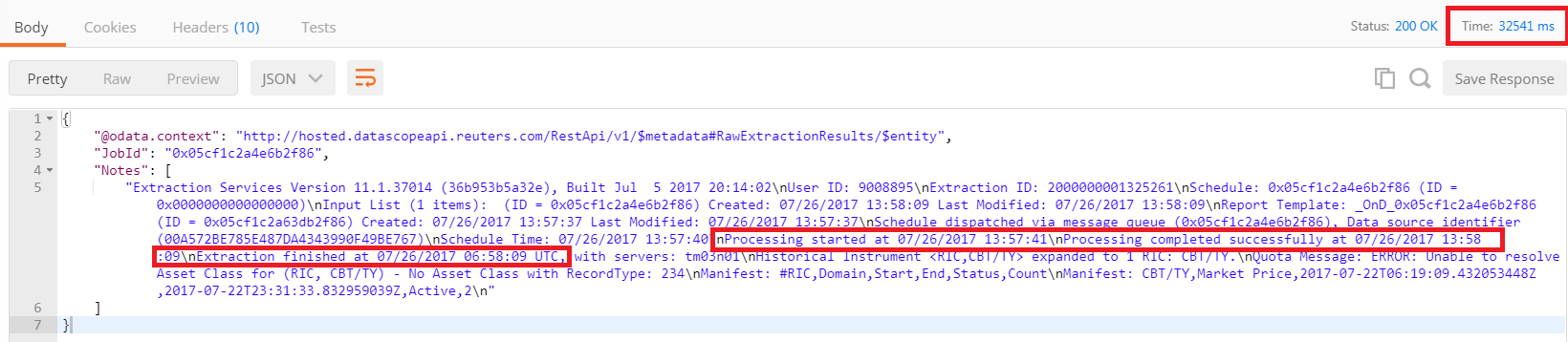
I tried to use the REST API to retrieve Speedguide pages, as explained in the user guide (v3.0) of Thomson Reuters Tick History 11.1 REST API Chapter 5. After figuring out that the error in the first reply can be ignored and I can go ahead looking for the ExtractionID and extract files in it, I can successfully get the data of the page as described in the manual. However, I found that it takes a really long time to get the page. When fetching manually, I usually get the page in 10 seconds. But when fetched with the REST API, it usually takes between 30 seconds to 1 minute in order to get a Speedguide page, in particular for the Extractions/ExtractRaw call to complete. Is there anything I can do to fetch the data faster? I attach my complete Python test program for reference.
import datetime
import getpass
import json
import os
import re
import time
import requests
def make_dss_odata(od_type, **kwargs):
"Make a dict object as DSS odata"
kwargs.update({'@odata.type': '#ThomsonReuters.Dss.Api.' + od_type})
return kwargs
class ReutersDSSCaller(object):
"Make REST API call to Reuters DataScope Select"
_BASEURL = 'https://hosted.datascopeapi.reuters.com/RestApi/v1'
def __init__(self, user, pw):
self._user = user
self._pw = pw
self._auth_token = None
def get(self, *args, **kwargs):
"Call REST get method"
return self._call('get', *args, **kwargs)
def put(self, *args, **kwargs):
"Call REST put method"
return self._call('put', *args, **kwargs)
def delete(self, *args, **kwargs):
"Call REST delete method"
return self._call('delete', *args, **kwargs)
def post(self, *args, **kwargs):
"Call REST post method"
return self._call('post', *args, **kwargs)
def _call(self, method, path, headers=(), body=None, parse=3, stream=False):
# pylint: disable=R0913
headers = dict(headers)
headers.setdefault('Authorization', 'Token ' + self.get_auth_token())
return self._raw_call(method, path, headers, body, parse, stream)
def get_auth_token(self):
"Get DSS REST API authentication token"
if not self._auth_token:
ret = self._raw_call('post', 'Authentication/RequestToken', {}, {
'Credentials': {
'Password': self._pw,
'Username': self._user
}
}, 3, False)
self._auth_token = ret
return self._auth_token
def _raw_call(self, method, path, extraheaders, body, parse, stream):
# pylint: disable=R0913
headers = {'Content-Type': 'application/json; odata.metadata=minimal'}
headers.update(extraheaders)
body_str = '' if body is None else json.dumps(body)
resp = getattr(requests, method)(self._BASEURL + '/' + path,
data=body_str, headers=headers,
stream=stream)
if parse <= 0:
return resp
if resp.status_code >= 400:
raise RuntimeError('DSS API Error %s: %s'
% (resp.status_code, resp.reason))
if parse <= 1 or stream:
return resp
ret = resp.json()
return ret if parse <= 2 else ret['value']
def download(self, resp, path):
"Download content in REST API response"
tmp_path = path + '.tmp'
with open(tmp_path, 'wb') as fout:
if path.endswith('.gz'):
content_iter = self._iter_raw_resp(resp, 1024 * 1024)
else:
content_iter = resp.iter_content(chunk_size=1024 * 1024)
for chunk in content_iter:
fout.write(chunk)
os.rename(tmp_path, path)
def _iter_raw_resp(self, resp, chunk_size):
while True:
chunk = resp.raw.read(chunk_size)
if len(chunk) == 0:
break
yield chunk
# Create caller
user_name = raw_input('DSS User name: ')
passwd = getpass.getpass('DSS password: ')
caller = ReutersDSSCaller(user_name, passwd)
page = raw_input('Speedguide page: ')
if not page:
page = 'CBT/TY'
print 'Using default,', page
# Submit extraction request
today = datetime.datetime.combine(datetime.date.today(), datetime.time())
start_date = today - datetime.timedelta(7)
print 'Initial call'
ret = caller.post(
'Extractions/ExtractRaw',
headers={'Prefer': 'respond-async'},
body={
'ExtractionRequest': make_dss_odata(
'Extractions.ExtractionRequests.'
'TickHistoryRawExtractionRequest',
IdentifierList=make_dss_odata(
'Extractions.ExtractionRequests.InstrumentIdentifierList',
ValidationOptions={'AllowHistoricalInstruments': True},
UseUserPreferencesForValidationOptions=False,
InstrumentIdentifiers=[
{'Identifier': page,
'IdentifierType': 'Ric'}
]
),
Condition={
'MessageTimeStampIn': 'GmtUtc',
'ReportDateRangeType': 'Range',
'QueryStartDate': start_date.isoformat(),
'QueryEndDate': today.isoformat(),
'ExtractBy': 'Ric',
'SortBy': 'SingleByRic',
'DomainCode': 'MarketPrice',
'DisplaySourceRIC': True
},
),
},
parse=1)
# Poll for completion
if ret.status_code == 202:
loc = ret.headers['location'].partition('/v1/')[2]
while ret.status_code == 202:
print 'Initial call retry'
time.sleep(5)
ret = caller.get(loc, headers={'Prefer': 'respond-async'}, parse=1)
print 'Initial call completed'
# Look for extraction ID
match = re.search(r'Extraction ID: ([0-9]+)\n', ret.json()['Notes'][0])
eid = match.group(1)
# List Report Files
file_list = caller.get('Extractions/ReportExtractions(\'%s\')/Files' % eid)
# Download the Files
for f_spec in file_list:
filename = f_spec['ExtractedFileName']
ret = caller.get('Extractions/ExtractedFiles(\'%s\')/$value'
% f_spec['ExtractedFileId'], stream=True)
print 'Downloading', filename
caller.download(ret, filename)