Hello
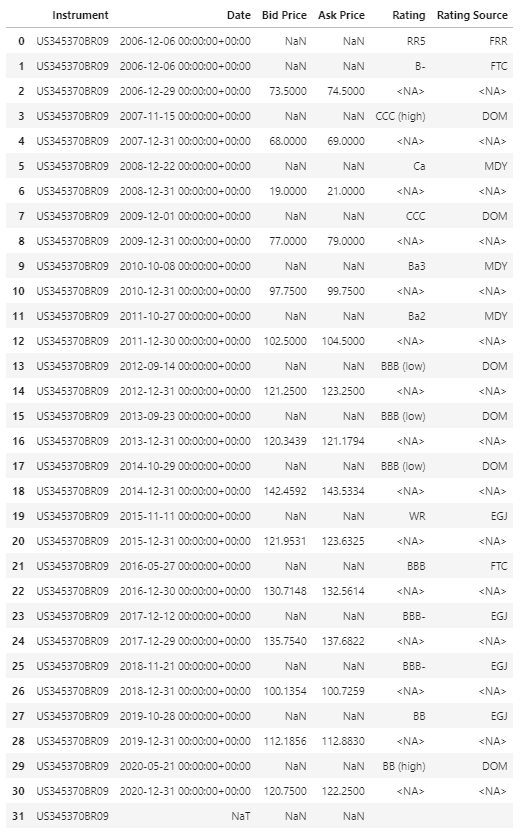
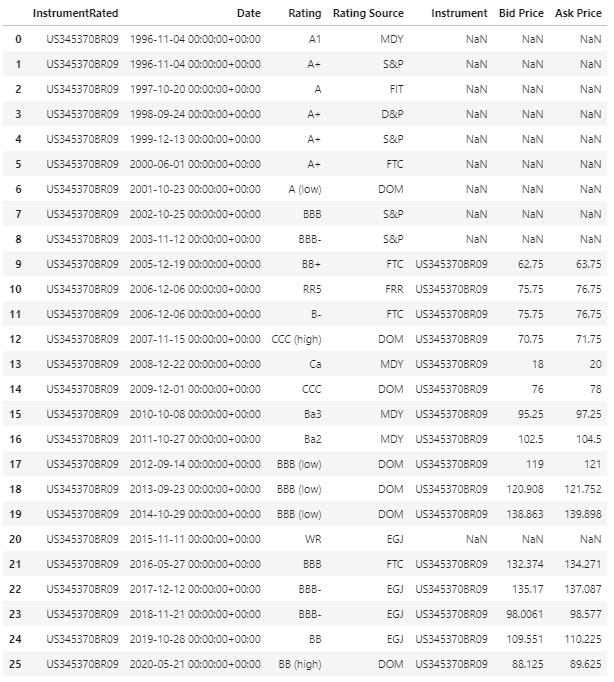
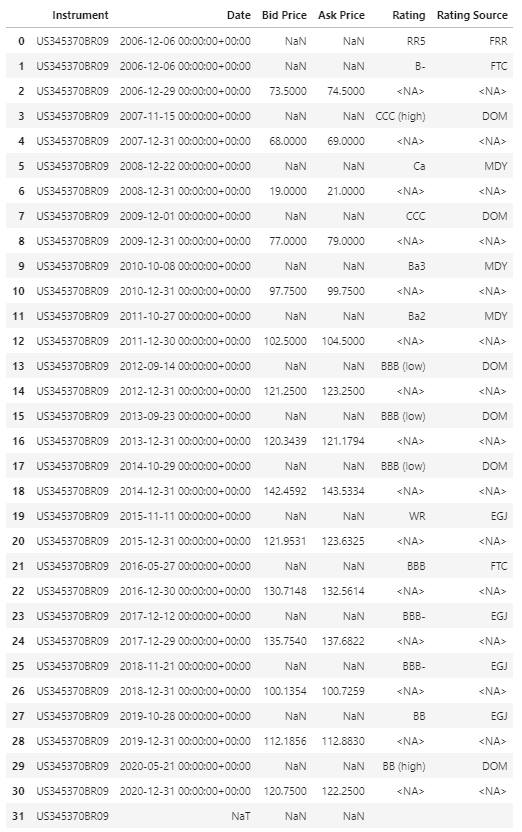
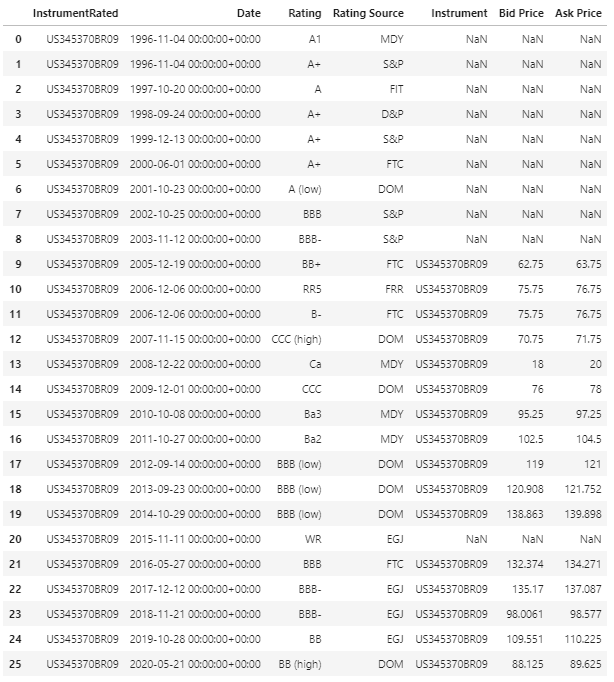
I am trying to retrieve yearly (end-of-year) credit ratings for a list of companies. I provide a sample code with a list of 2 companies here. I am running the following:
df2, err = ek.get_data(['US0378331005','US345370BR09'], ['TR.BIDPRICE.date', 'TR.BIDPRICE', 'TR.ASKPRICE','TR.GR.Rating(BondRatingSrc=MDY)',
'TR.GR.Rating(BondRatingSrc=FTC)','TR.GR.Rating(BondRatingSrc=SPI)'],
{'SDate':'-12Y','EDate':'0', 'FRQ':'Y'})
df2.columns = df2.columns[:-3].tolist() + ['Moody\'s Rating','Fitch Rating','SP Rating']
df2
Can somebody confirm that I am doing the right thing above?
Two problems:
1. S&P Ratings are not showing at all. They are all blank
2. Even within Moody's, there are blanks in some years. E.g. for the second company in the list, I get a rating in 2013, then blank for 2014, 2015, and a new rating in 2016. How do I fill these gaps?

{kind=link}
{kind=link}