When client subscribe platts through DSS, they can get daily corrections file in extraction. How can they extract that Corrections detail through API?
For a deeper look into our DataScope Select SOAP API, look into:
Overview | Quickstart | Documentation | Downloads | Tutorials
{kind=link}
462
●9 ●7 ●14
Hi Veerapath,
Thanks for finding out the answer from Jiajia and Bob.
Posting it below in case anyone else has the same question.
Both use GET (can be used in internet browser), step:
1) endpoint https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/OtherFiles/ then
2) use https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/OtherFiles('{OtherFileId }')/$value to get the content.
Cheers,
Gareth

Thank you for sharing the information. Glad to know that the method works.:)
11.3k
●25 ●8 ●13
Hi @tao.yuan,
To retrieve last extraction file, you need to know Schedule ID by using GetByName endpoint with Schedule name.(i.e. "PlattsCorrections"). The Schedule ID should not be changed for a schedule, so application can store and reuse the ID for next retrieval.
Below is the sample of request.
Request:
GET https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/ScheduleGetByName(ScheduleName='PlattsCorrections')
Response:
{
"@odata.context": "https://hosted.datascopeapi.reuters.com/RestApi/v1/$metadata#Schedules/$entity",
"ScheduleId": "0x05b6ab1f77eb3026",
"Name": "PlattsCorrections",
"OutputFileName": "",
"TimeZone": "SE Asia Standard Time",
"Recurrence": {
...
Below are the steps to get the extraction result from Schedule ID via API.
1) Get last Report Extraction ID for the Schedule ID using Schedule.LastExtraction.
Your corrections file is generated daily, so the schedule should be recurring. You need to get only last extraction information.
In this sample, the Schedule ID is '0x05b6ab1f77eb3026'. The last Report Extraction ID received in this sample is '2000000087212479'.
Request:
GET https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/Schedules('0x05b6ab1f77eb3026')/LastExtraction
Response:
{
"@odata.context": "https://hosted.datascopeapi.reuters.com/RestApi/v1/$metadata#ReportExtractions/$entity",
"ReportExtractionId": "2000000087212479",
"ScheduleId": "0x05b6ab1f77eb3026",
"Status": "Completed",
...
2) Get Extracted File ID of extracted data using ReportExtraction.FullFile.
Normally an extraction will generate two files; data and Notes. You need to get ExtractedFileId for data file. The Extracted File ID for data file in this sample is 'VjF8fDUwNjM3NTg2OQ'
Request:
GET https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/ReportExtractions('2000000087212479')/FullFile
Response:
{
"@odata.context": "https://hosted.datascopeapi.reuters.com/RestApi/v1/$metadata#ExtractedFiles/$entity",
"ExtractedFileId": "VjF8fDUwNjM3NTg2OQ",
"ReportExtractionId": "2000000087212479",
"ScheduleId": "0x05b6ab1f77eb3026",
"FileType": "Full",
...
3) Retrieve data with ExtractedFileId using GetDefaultStream.
Finally, you can retrieve the extracted data.
Request:
GET https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/ExtractedFiles('VjF8fDUwNjM3NTg2OQ')/$value
For more detailed information, please see this GUI control calls: immediate extract tutorial.
462
●9 ●7 ●14
Hi,
I also need some help with this please. This thread seems like the same question so thought it was relevent not to raise a new thread.
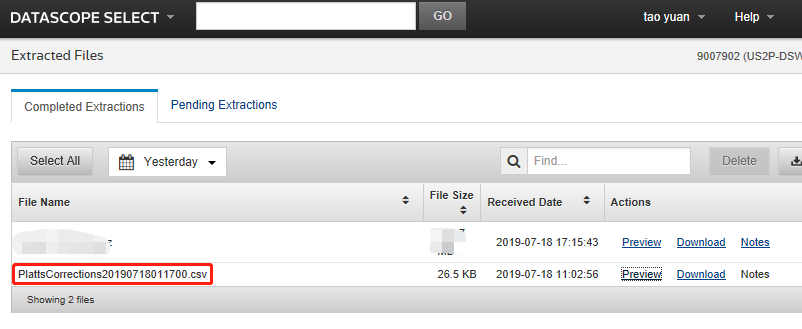
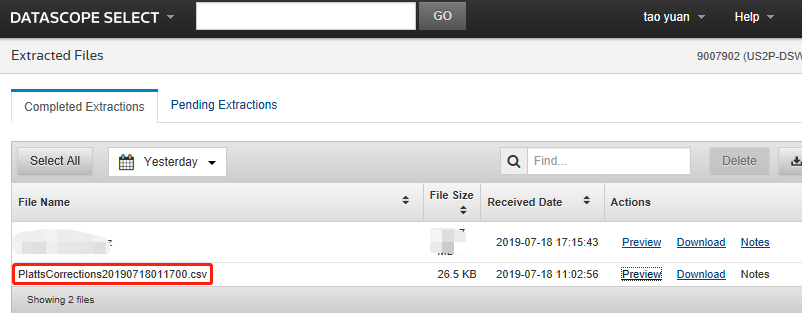
So I also get Platts Corrections files generated into my DSS User ID. This appears to be done daily and looks like the below:
However, and this is where I think the above workflow doesn't work for these files specifically. These are files which are placed into a user's Extracted Files based on a specific permission/service, and not generated through a user's schedule (so no schedule will exist for me to use), and no Notes are generated.
Indeed I had thought there maybe some kind of hidden reserved name but...:
Gave me:
{
"error": {
"message": "Exception of type 'ThomsonReuters.Dss.Core.Exceptions.NotFoundException`1[ThomsonReuters.Dss.Api.Extractions.Schedules.Schedule]' was thrown."
}
}
I need to be able to get to ExtractedFileId for use with Get Read Stream in the minimum number of steps to:
How can I do this please?
Many thanks,
Gareth
On doing a bit more investigation it seems this is expected and is handled by endpoint:
GET https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/ReportExtractionGetOtherFiles
Though I still need to know the step(s) to get to stream...if anyone know hoping they can help.
Also found: https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/OtherFiles not sure if/how differs to: https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/ReportExtractionGetOtherFiles ?
I have done some search. Yes, you are correct. The PlattsCorrection is generated automatically by DSS, not a user's schedule. So, this method I provided may not work. I will contact DSS support for the question.