客户使用我司提供的DSS Rest API C# example(附件),每日抓取一个数据文件,遇到两个问题:
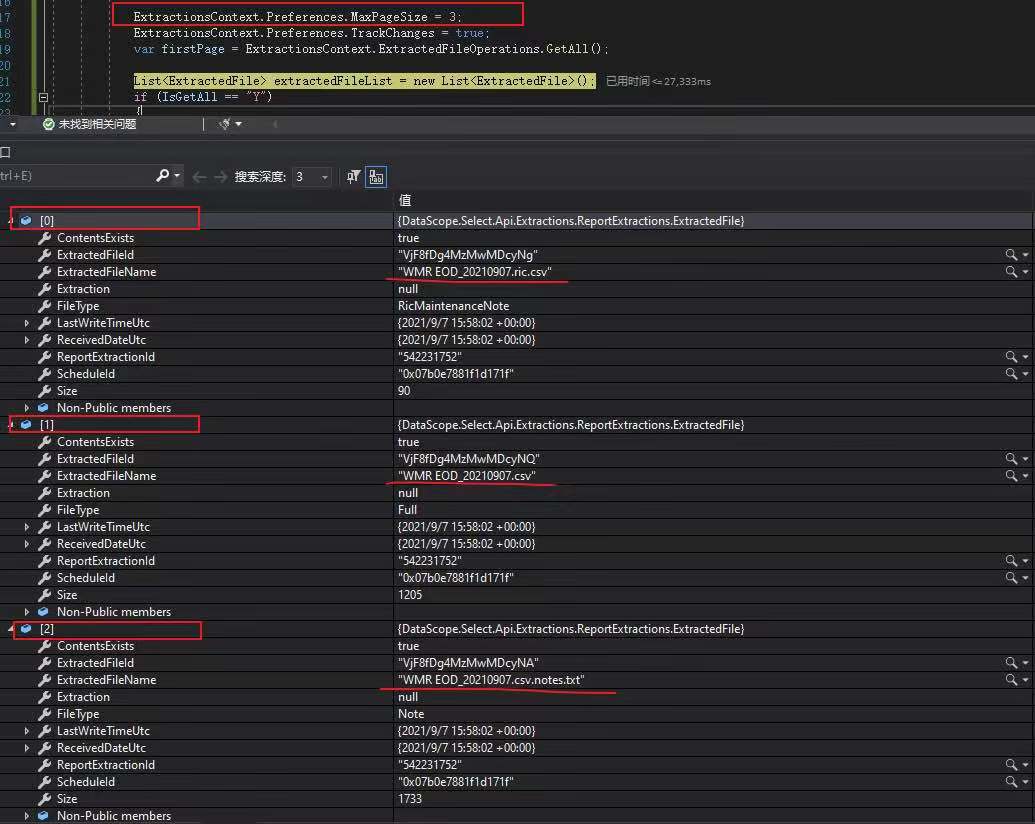
1)客户已删除的文件还可以通过接口全部取到(已删除文件size=0)
2)客户只想获取数据文件,不想获取RIC list和Note
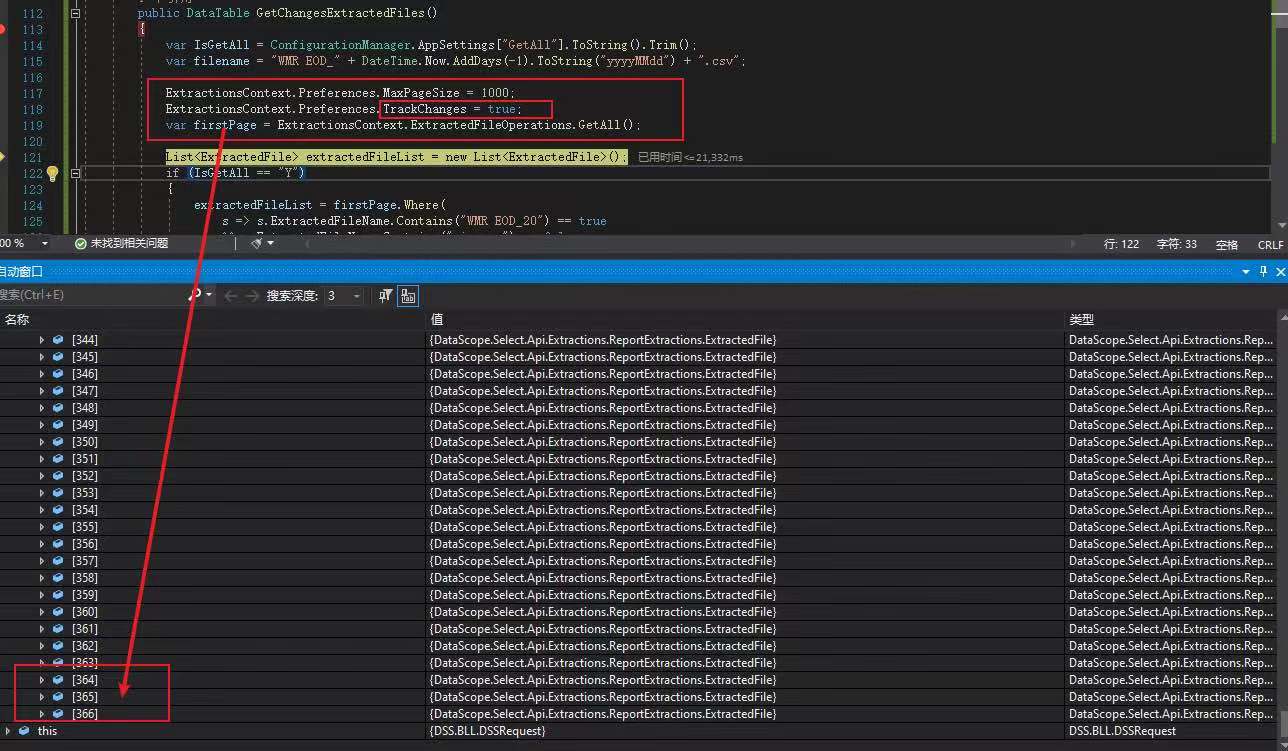
建议客户尝试了Get latest和Get Changes,都返回同样的结果,如附件两张snapshot
请帮忙检查哪个API参数需要变更,只获得最新的数据文件,多谢
#region Extracted Files
[Example("Get Latest")]
public void GetLatest()
{
/* This example provides an alternate mechanism for retrieving the extraction contents for a schedule or schedules.
* The preferred approach is to use the WaitForNextExtraction method on the toolkit (or LastExtraction association
* property). The MaxPageSize defaults to 250 and should be kept at the default. If the first page's results have
* the HasNextPage set to true then more data is available. You can continue to retrieve subsequent pages using
* GetAll and passing in the next link. When no more data is available, HasNextPage will be false. */
ExtractionsContext.Preferences.MaxPageSize = 3; //Only set for the purposes of the example
Status.Notify(ExtractionsContext, "ReportExtraction", "GetAll", MethodType.Operation, Publish.Primary);
//Returns the first page (250) of the latest Report Extractions for all Schedules.
var firstPage = ExtractionsContext.ReportExtractionOperations.GetAll();
//Output
//Use the schedule id to determine which schedule the results are associated to.
Status.WriteLine("FIRST PAGE:");
foreach (var reportExtraction in firstPage)
Status.WriteLine("ScheduleName: {0}, Date: {1}",
reportExtraction.ScheduleName, reportExtraction.ExtractionDateUtc);
Status.EndNotify(ExtractionsContext);
Status.Notify(ExtractionsContext, "ReportExtraction", "GetAll", MethodType.Operation, Publish.Secondary);
//Only get the second page of data if data is available.
if (firstPage.HasNextPage)
{
//Returns the second page. Notice that NextLink is passed to GetAll.
var secondPage = ExtractionsContext.ReportExtractionOperations.GetAll(firstPage.NextLink);
//Output
Status.WriteLine("SECOND PAGE:");
foreach (var reportExtraction in secondPage)
Status.WriteLine("ScheduleName: {0}, Date: {1}",
reportExtraction.ScheduleName, reportExtraction.ExtractionDateUtc);
}
Status.EndNotify(ExtractionsContext);
}
#endregion
#region Extracted Files
[Example("ExtractedFiles: Get Latest")]
public void ExtractedFilesGetLatest()
{
/* This example provides an alternate mechanism for retrieving the extraction contents for a schedule or schedules.
* The preferred approach is to use the WaitForNextExtraction method on the toolkit (or LastExtraction association
* property). The MaxPageSize defaults to 250 and should be kept at the default. If the first page's results have
* the HasNextPage set to true then more data is available. You can continue to retrieve subsequent pages using
* GetAll and passing in the next link. When no more data is available, HasNextPage will be false. */
ExtractionsContext.Preferences.MaxPageSize = 3; //Only set for the purposes of the example
Status.Notify(ExtractionsContext, "ExtractedFile", "GetAll", MethodType.Operation, Publish.Primary);
//Returns the first page (250) of the latest Extracted Files for all Report Extractions for all Schedules.
var firstPage = ExtractionsContext.ExtractedFileOperations.GetAll();
//Output
//Use the schedule id to determine which schedule the results are associated to.
Status.WriteLine("FIRST PAGE:");
foreach (var extractedFile in firstPage)
Status.WriteLine("ScheduleId: {0}, Filename: {1}, Size: {2}, ContentsExist: {3}",
extractedFile.ScheduleId, extractedFile.ExtractedFileName, extractedFile.Size, extractedFile.ContentsExists);
Status.EndNotify(ExtractionsContext);
Status.Notify(ExtractionsContext, "ExtractedFile", "GetAll", MethodType.Operation, Publish.Secondary);
//Only get the second page of data if data is available.
if (firstPage.HasNextPage)
{
//Returns the second page of Extracted Files. Notice that NextLink is passed to GetAll.
var secondPage = ExtractionsContext.ExtractedFileOperations.GetAll(firstPage.NextLink);
//Output
//Use the schedule id to determine which schedule the results are associated to.
Status.WriteLine("SECOND PAGE:");
foreach (var extractedFile in secondPage)
Status.WriteLine("ScheduleId: {0}, Filename: {1}, Size: {2}, ContentsExist: {3}",
extractedFile.ScheduleId, extractedFile.ExtractedFileName, extractedFile.Size, extractedFile.ContentsExists);
}
Status.EndNotify(ExtractionsContext);
}
[Example("ExtractedFiles: Get Changes")]
public void ExtractedFilesGetChanges()
{
/* This example provides an alternate mechanism for retrieving the extraction contents for a schedule or schedules.
* The preferred approach is to use the WaitForNextExtraction method on the toolkit (or LastExtraction association
* property).
* If Change Tracking is enabled the server returns a delta token along with the payload. If the delta token is
* presented on a subsequent request only records that have changed since the prior request are returned.
* NOTE: Paging is in effect along with change tracking. */
ExtractionsContext.Preferences.MaxPageSize = 3; //Only set for the purposes of the example
ExtractionsContext.Preferences.TrackChanges = true; //Let the API know that you are interested in tracking changes.
Status.Notify(ExtractionsContext, "ExtractedFile", "GetAll", MethodType.Operation, Publish.Secondary);
//Get all the results. The results are paged so that a maximum of 250 are returned. Because TrackChanges was set to
//true, firstPage.DeltaLink includes a token that can be used to find any changes that were made since this request.
//If you _really_ wanted all the results here you would have to call GetAll with all.NextLink until HasNextPage is
//false.
var all = ExtractionsContext.ExtractedFileOperations.GetAll();
//Output
Status.WriteLine("ALL:");
//NOTE: DeltaLink's can be persisted using DeltaLink.ToString() and DeltaLink.Parse().
Status.WriteLine("DeltaLink: " + all.DeltaLink.Url);
foreach (var extractedFile in all)
Status.WriteLine("ScheduleId: {0}, Filename: {1}, Size: {2}, ContentsExist: {3}",
extractedFile.ScheduleId, extractedFile.ExtractedFileName, extractedFile.Size, extractedFile.ContentsExists);
Status.EndNotify(ExtractionsContext);
Status.Notify(ExtractionsContext, "ExtractedFile", "GetAll", MethodType.Operation, Publish.Secondary);
//Get all the ExtractedFiles that have changed since the original request. Note that these results can also be paged
//which means that you would need to call GetAll with changed.NextLink while changed.HasNextPage is true.
var changed = ExtractionsContext.ExtractedFileOperations.GetAll(all.DeltaLink);
//Output
Status.WriteLine("CHANGES:");
//In this example there will be no changes since no extractions were likely to have run between these two calls to
//GetAll.
foreach (var extractedFile in changed)
Status.WriteLine("ScheduleId: {0}, Filename: {1}, Size: {2}, ContentsExist: {3}",
extractedFile.ScheduleId, extractedFile.ExtractedFileName, extractedFile.Size, extractedFile.ContentsExists);
Status.EndNotify(ExtractionsContext);
}
#endregion

{kind=link}
{kind=link}