I am trying to use for loop to get ESG news headlines for a list of 405 companies.
My code has proven succesfull when retrieving RICs based on ISINs, however, when I apply the same approach to retrieve the news headlines, I get the error "query must be string ". When I try to use "str()" to convert the values into string, and run the for loop, I get the error below:
EikonError: Error code 500 | Backend error. Failed to deserialize backend response. Expected valid JSON. Error: invalid character 'i' looking for beginning of value
See example below of the instance where my for loop code works with the "ek.get_symbology" function, and how it fails with the "ek.get_news_headlines" function.
Succesful example with ek.get_symbology:
## Ensuring that all ISIN ID's in the Brands data frame are strings (or otherwise converting them)
Brands["ID (ISIN)"] = Brands["ID (ISIN)"].astype(str)
## Creating a list of all the ISINs in order to make the RIC call on the API
ISIN_List = Brands["ID (ISIN)"].tolist()
## Dividing the list of 450 compaies into chunks for the API to be able to process it
chunklist = chunk(ISIN_List, 100)
##Calling RICs from API based on ISIN's (with a for loop to batch the request in chunks)
content_df = []
for subs in chunklist:
RICs = ek.get_symbology(subs, from_symbol_type='ISIN', to_symbol_type= 'RIC')
content_df.append(RICs)
content_df = pd.concat(content_df)
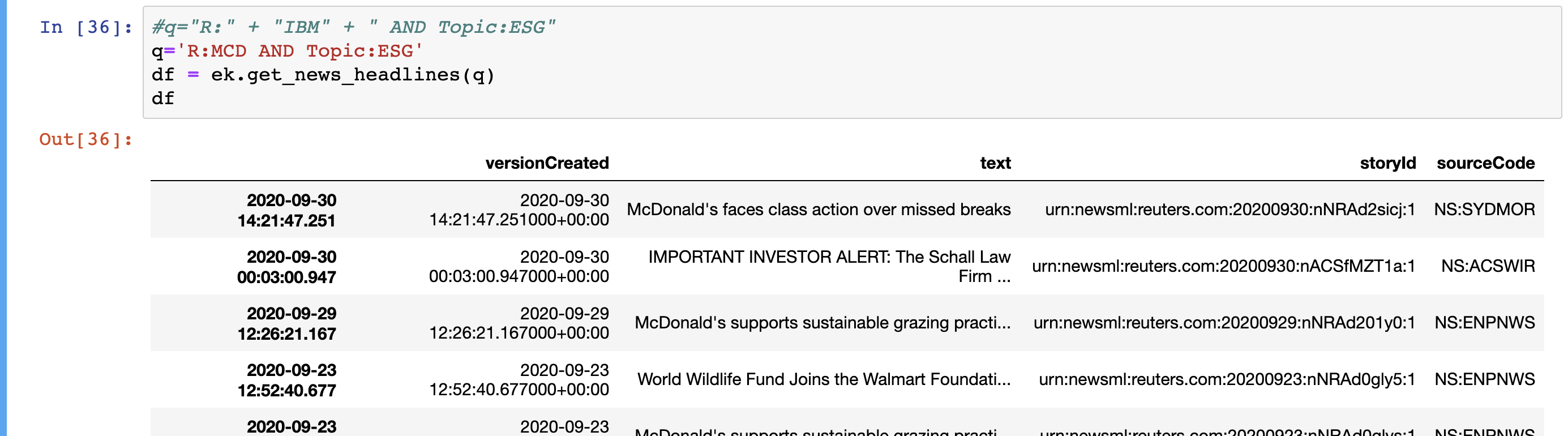
Failed attempt with the "ek.get_news_headlines" function.
##Adding the "R:" for insturment clarification + ESG as a topic for the headline retriever
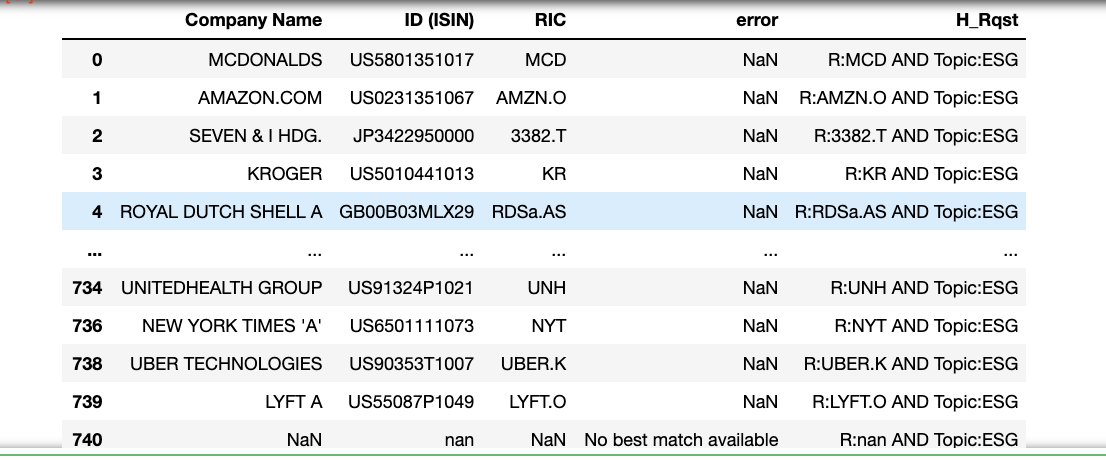
Brands_M["H_Rqst"] = "R:"+ Brands_M["RIC"].map(str) + " AND Topic:ESG"
## Ensuring that all Headline Request in the Brands data frame are strings (or otherwise converting them)
Brands_M["H_Rqst"] = Brands_M["H_Rqst"].astype(str)
##Creating list of RICs codes with ESG topic to call on the API
H_Q_List = Brands_M["H_Rqst"].tolist()
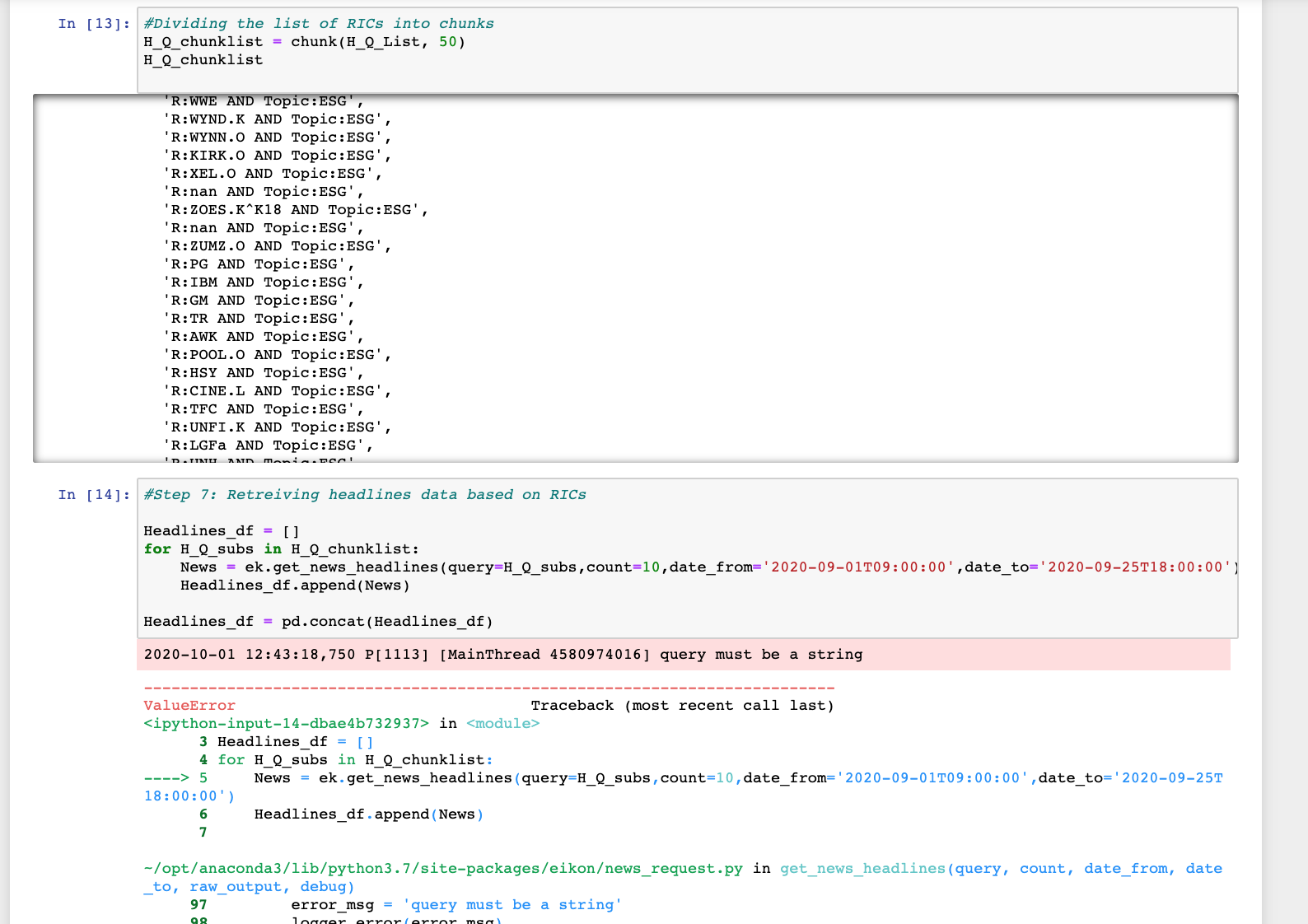
##Dividing the list into chunks for the API to process it
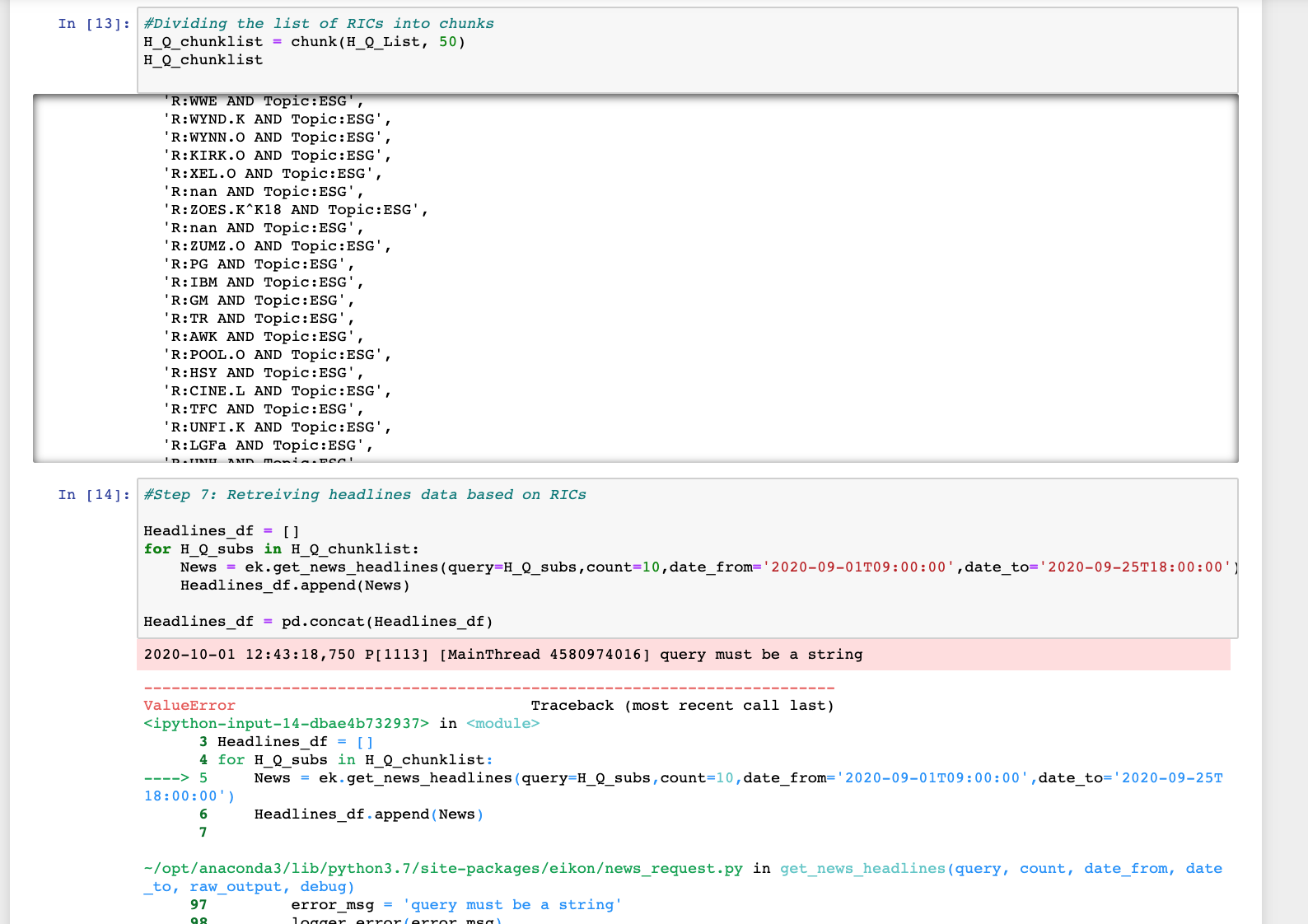
H_Q_chunklist = chunk(H_Q_List, 50)
##Retreiving headlines data based on RICs + ESG as a Topic
Headlines_df = []
for H_Q_subs in H_Q_chunklist:
News = ek.get_news_headlines(query=H_Q_subs,count=10,date_from='2020-09-01T09:00:00',date_to='2020-09-25T18:00:00')
Headlines_df.append(News)
Headlines_df = pd.concat(Headlines_df)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-13-dbae4b732937> in <module>
3 Headlines_df = []
4 for H_Q_subs in H_Q_chunklist:
----> 5 News = ek.get_news_headlines(query=H_Q_subs,count=10,date_from='2020-09-01T09:00:00',date_to='2020-09-25T18:00:00')
6 Headlines_df.append(News)
7
~/opt/anaconda3/lib/python3.7/site-packages/eikon/news_request.py in get_news_headlines(query, count, date_from, date_to, raw_output, debug)
97 error_msg = 'query must be a string'
98 logger.error(error_msg)
---> 99 raise ValueError(error_msg)
100
101 if type(count) is not int:
ValueError: query must be a string
Hope you can help, I suspect it has something to do with the addition of the topic.


{kind=link}
{kind=link}