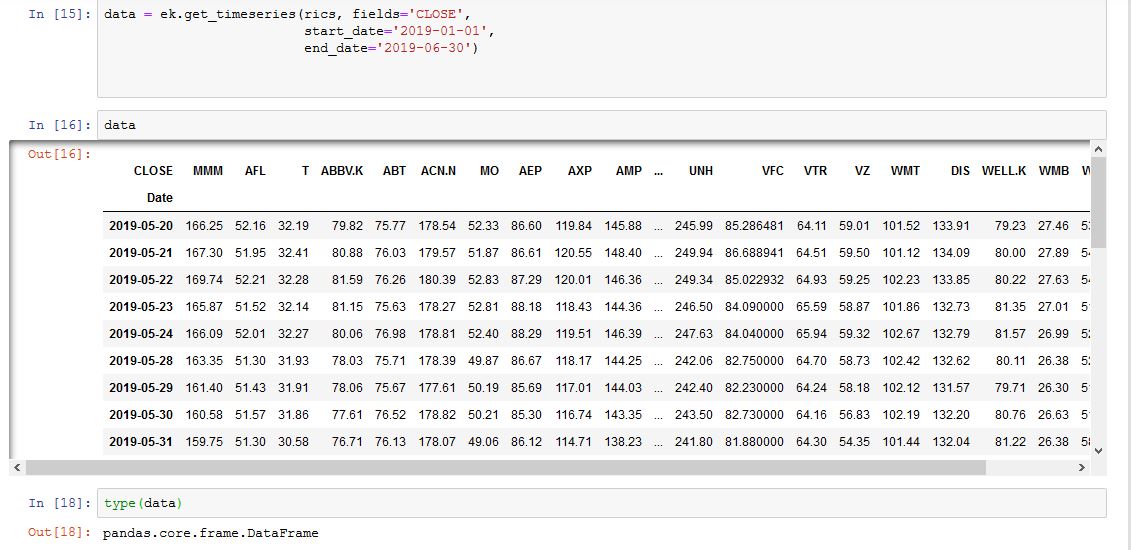
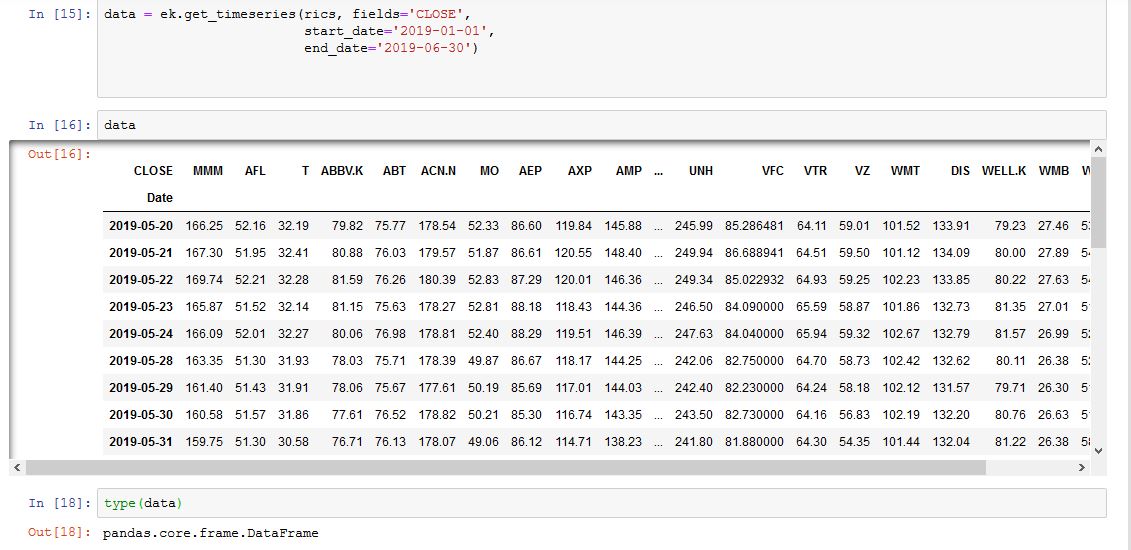
I have this code:
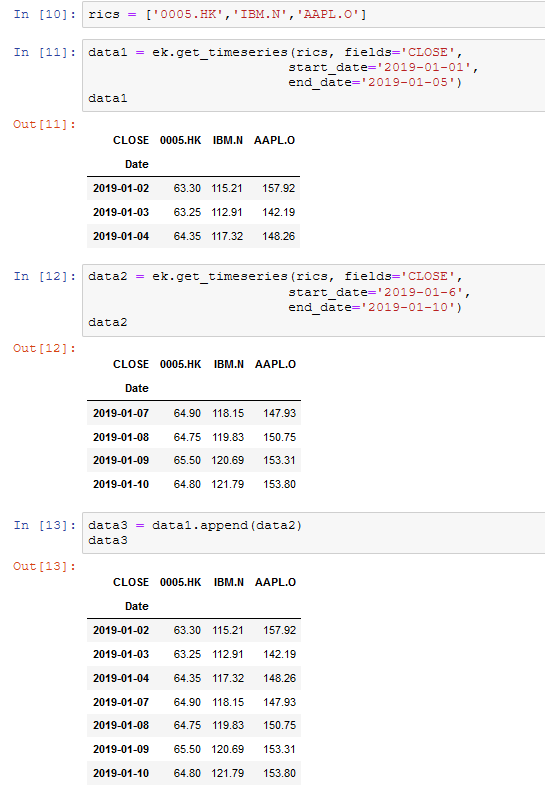
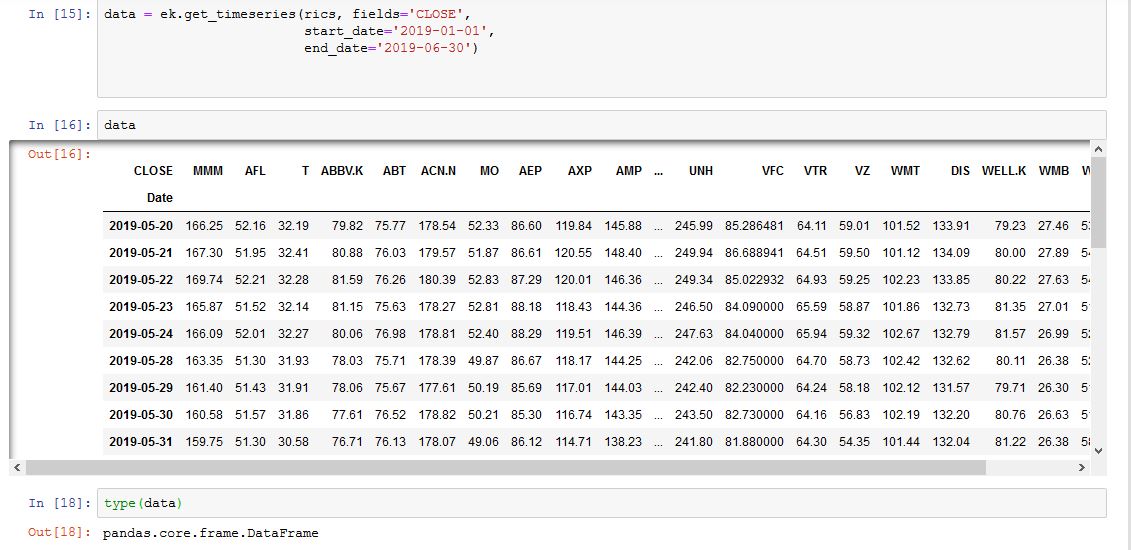
data = ek.get_timeseries(rics, fields='CLOSE',
start_date='2019-01-01',
end_date='2019-06-30')
but it returns data starting 5/20/2019 and ignores the start_date declared in the code:
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 29 entries, 2019-05-20 to 2019-06-28 Columns: 103 entries, MMM to YUM dtypes: float64(103) memory usage: 23.6 KB
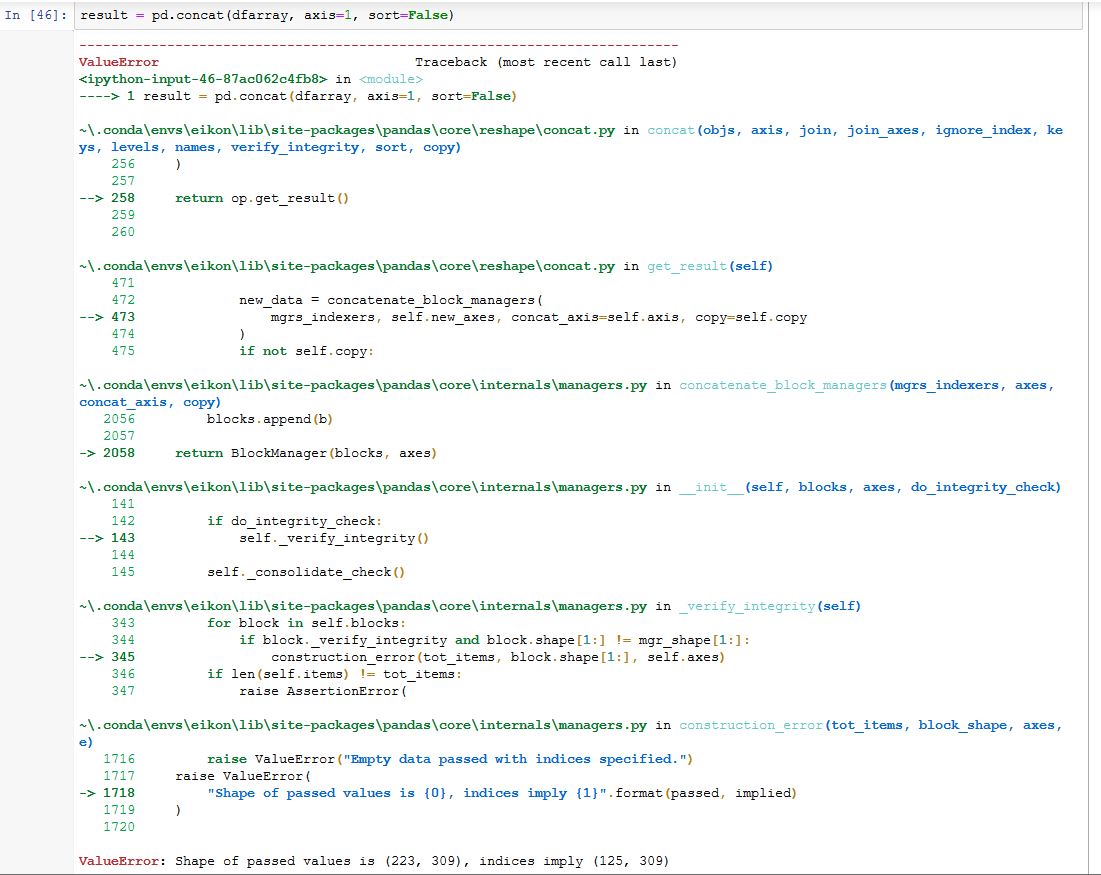
Based on other posts, it appears to be related to the 3000 shared row limit.
Here is a snippet of what I'd like returned - with daily closing price dates going back to 1/1/2019 for 103 equity tickers in total:
Close Date MMM AFL T ABBV ABT
2019-05-28 163.35 51.30 31.93 78.03 75.71
2019-05-29 161.40 51.43 31.91 78.06 75.67
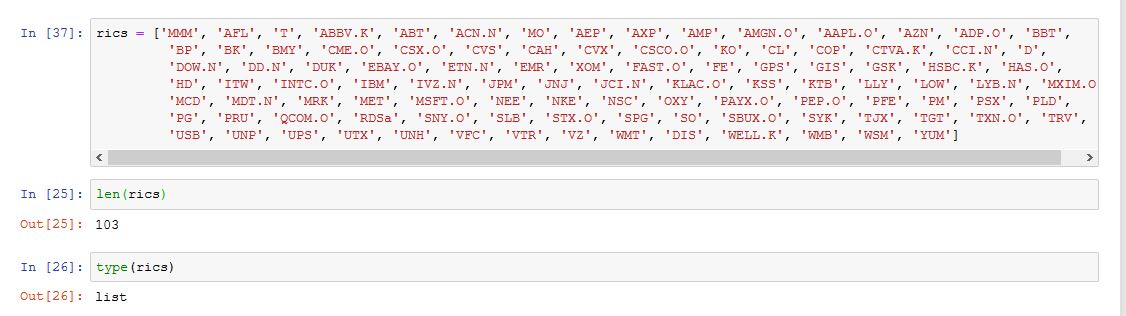
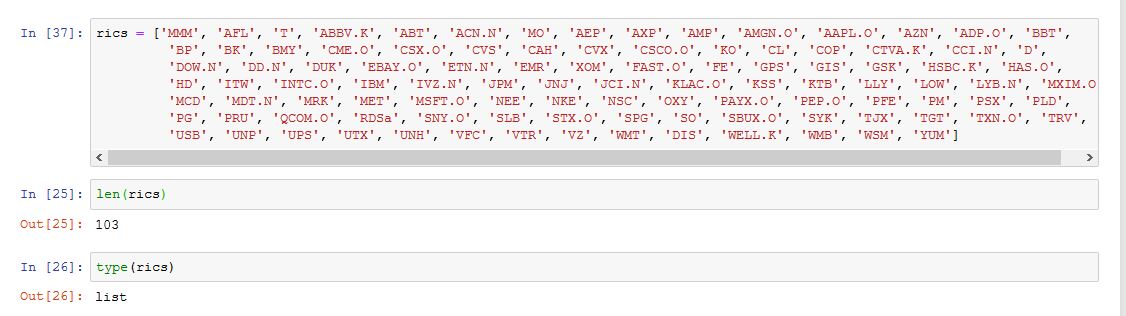
Here is my current data retrieval code:
'rics' is a list of tickers
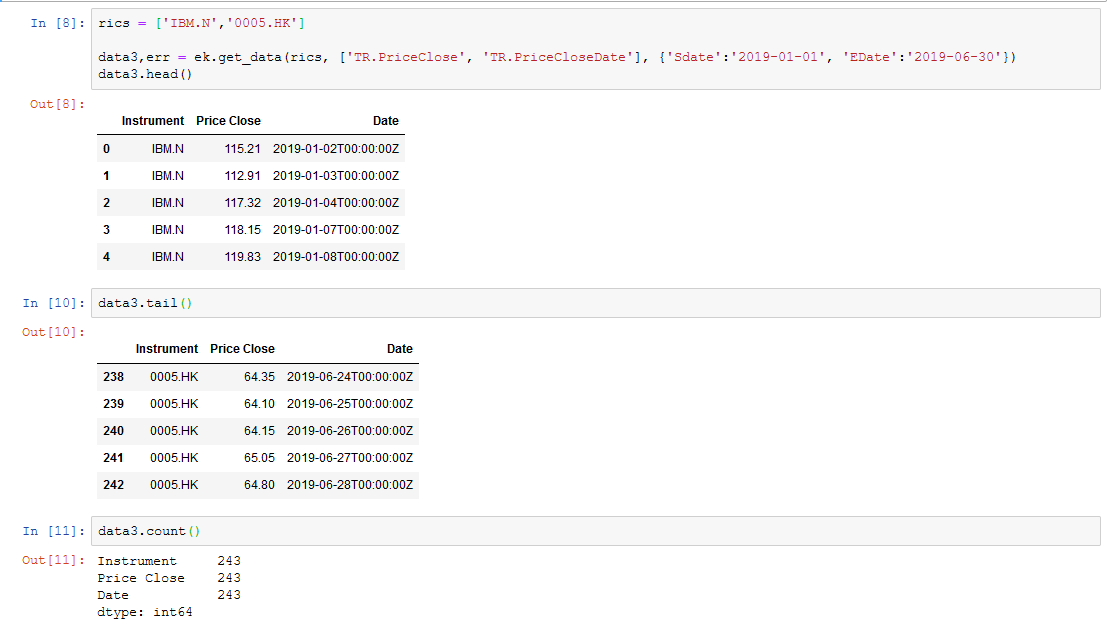
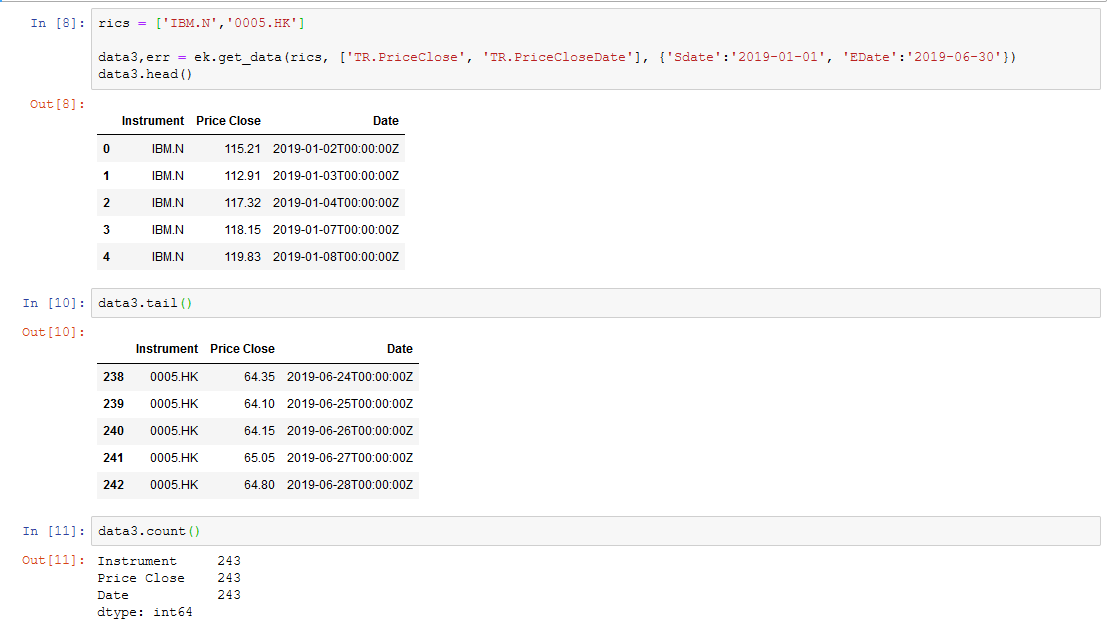
data3 = ek.get_data(rics, ['TR.PriceClose', 'TR.PriceCloseDate'], {'Sdate':'2019-01-01', 'EDate':'2019-06-30'})
But it returns a tuple:
( Instrument Price Close Date 0 MMM 190.95 2019-01-02T00:00:00Z 1 MMM 183.76 2019-01-03T00:00:00Z 2 MMM 191.32 2019-01-04T00:00:00Z 3 MMM 190.88 2019-01-07T00:00:00Z 4 MMM 191.68 2019-01-08T00:00:00Z ... ... ... ... 12767 YUM 110.66 2019-06-24T00:00:00Z 12768 YUM 110.31 2019-06-25T00:00:00Z 12769 YUM 110.12 2019-06-26T00:00:00Z 12770 YUM 110.56 2019-06-27T00:00:00Z 12771 YUM 110.67 2019-06-28T00:00:00ZI'm having trouble setting up 'get_data()' to return a dataframe, instead of a tuple.
Can you please provide some guidance to correct?
Thank you

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}