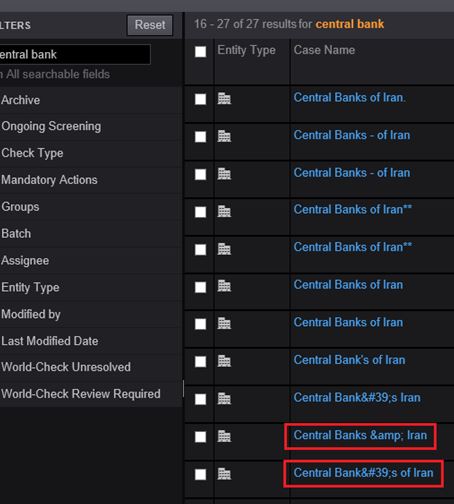
For World Check One screening, we use HTML encoding for organization names and UTF-8 encoding for entire post data. It works without any issue for most of the special characters. However, for ampersand (&) and apostrophes (‘), it converts those characters into & and ' when case is created in World Check One and match results change. You can refer attached screenshot.
Do you recommend not to use HTML encoding? Does UTF-8 encoding take care of all special characters and no other encoding is needed?
specialchar-issue.jpg
{kind=link}