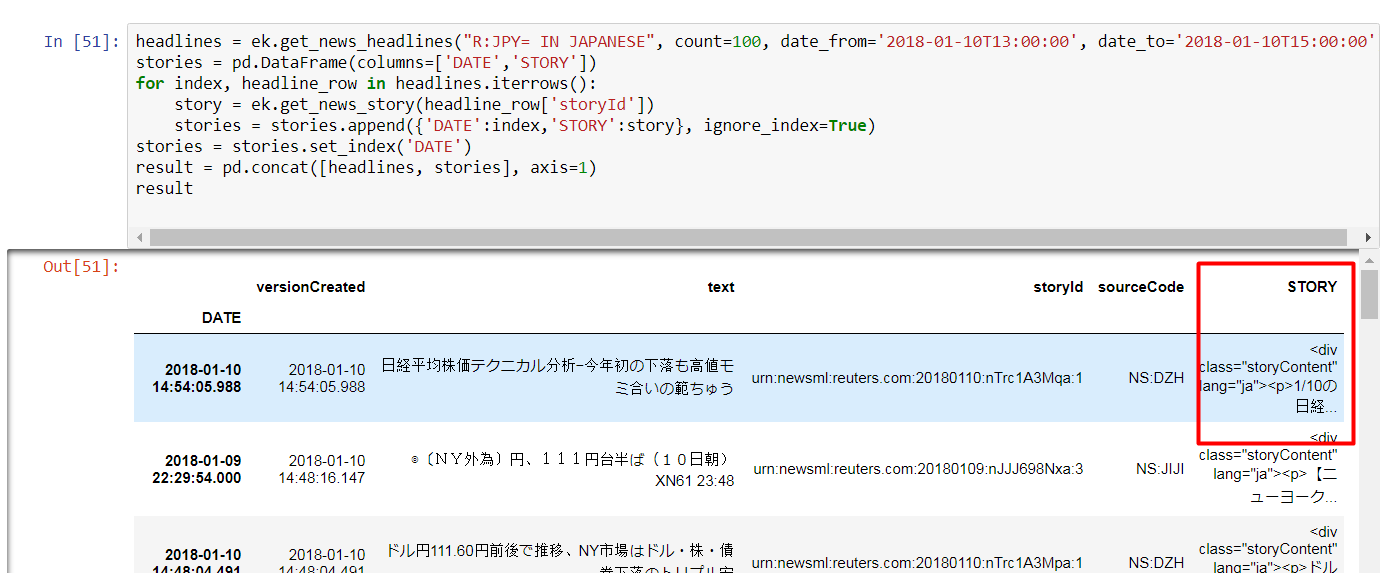
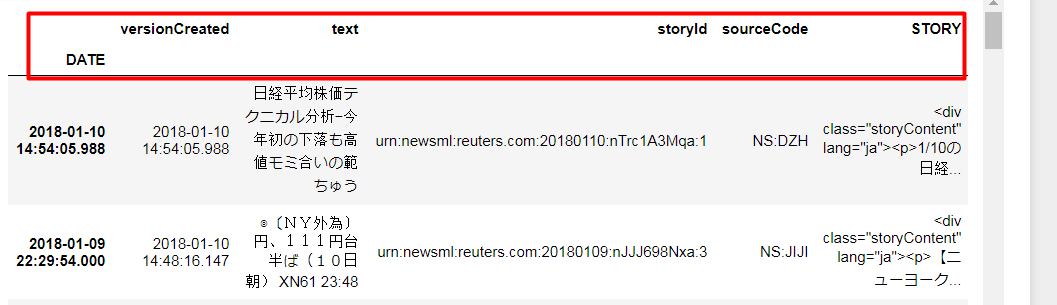
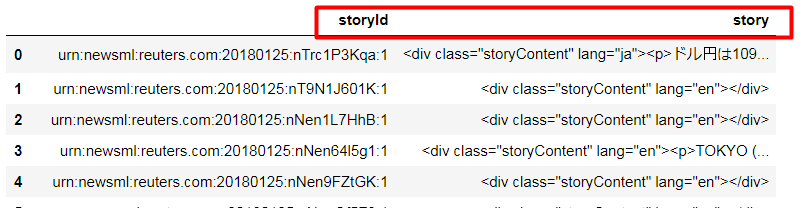
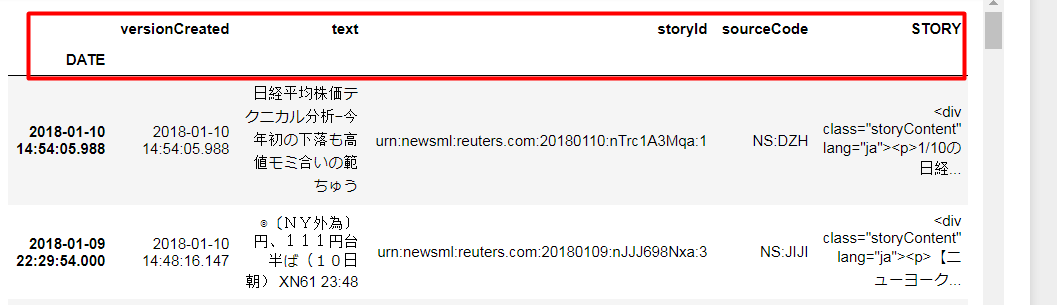
Hi,
I would like to make csv file of news headlines and story.
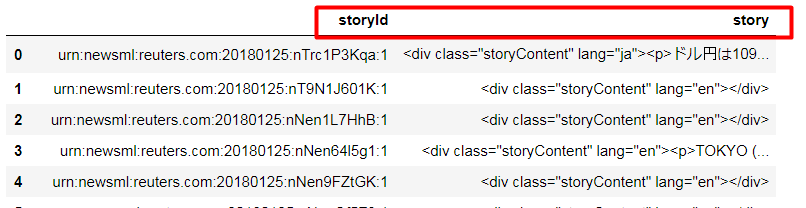
for headline I’m using→headlines = ek.get_news_headlines('JPY=')
for story I’m using →for index, headline_row in headlines.iterrows():
story = ek.get_news_story(headline_row['StoryId'])
print (story)
then request, df.to_csv('news.csv')
Does anyone know where do I have to fix?
Regards

{kind=link}
{kind=link}