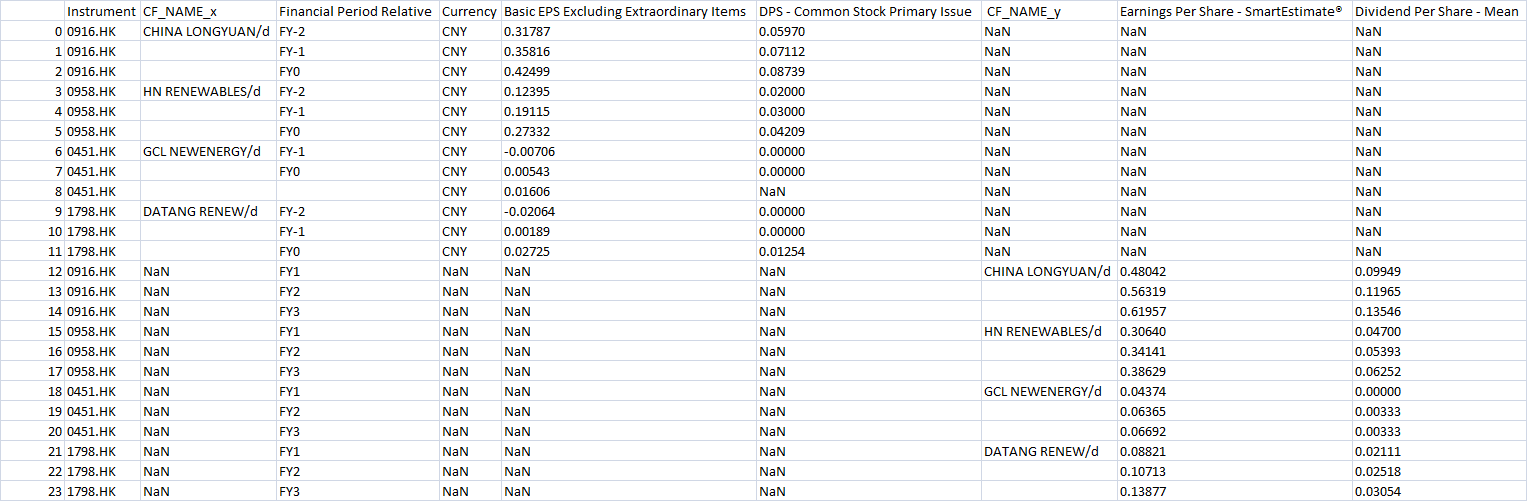
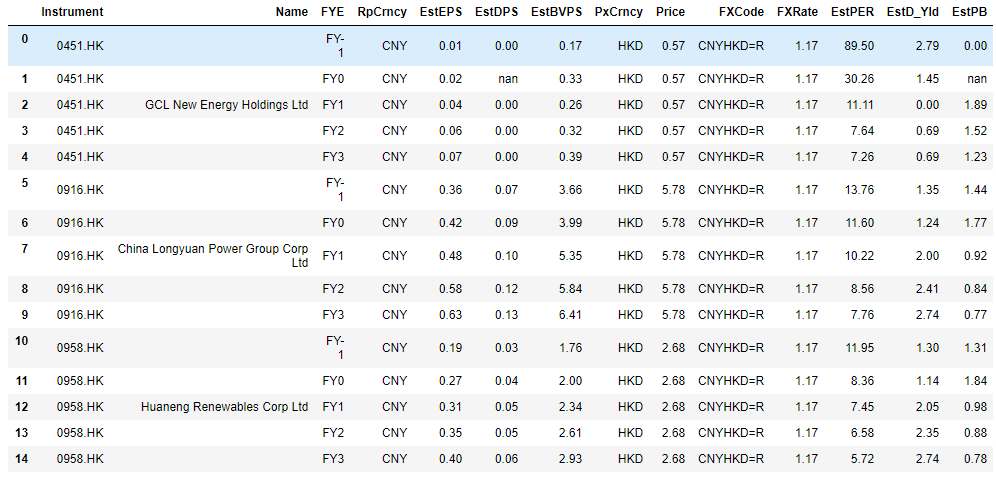
I get duplicate cells when I merge two dataframes: one containing historical data, a second containing forecast data, as follows:
tkrrenew = ['0916.HK', '0958.HK', '0451.HK', '1798.HK']
fdflds = ['CF_NAME', 'TR.EBITDA.rfperiod', 'TR.BasicEpsExclExtraItems.Currency', 'TR.BasicEpsExclExtraItems', 'TR.DpsCommonStock']
param = {'Period': 'FY0', 'SDate': 'FY-2', 'EDate': 'FY0', 'FRQ': 'FY'}
valrenew, err = ek.get_data(tkrrenew, fdflds, param)
frcstfld = ['CF_NAME', 'TR.EPSSmartEst.rfperiod', 'TR.EPSSmartEst', 'TR.DPSMean']
paramfcst = {'Period': 'FY1', 'SDate': '0', 'EDate': '2', 'FRQ': 'FY'}
fcstrenew, err = ek.get_data(tkrrenew, frcstfld, paramfcst)
testrenew = valrenew.merge(fcstrenew, on=['Instrument', 'Name'], how='inner')
The output, after some other commands is as follows:
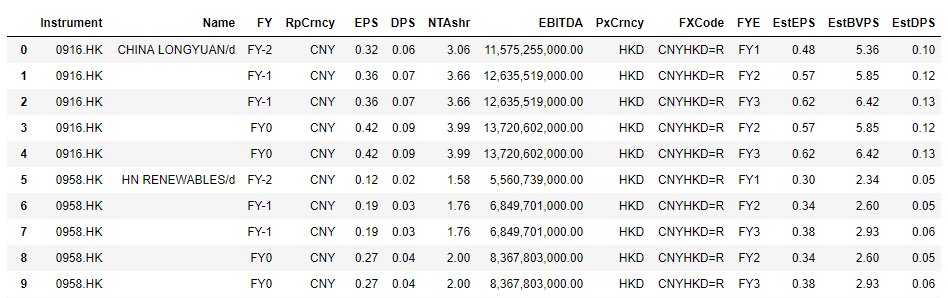
Apart from .drop_duplicate(subset=['Instrument', 'FY']) which leaves me with:

What can I do to have both historical and forecast data till FY3 in one dataframe. If .join or .append can place the FY1-FY3 in the same column as FY-2 to FY0, that would ideal.
Pls advise.